16 Sep 2015
·
Di Wu
·
In our app, users are assigned a default profile picture upon account creation. We used to have a
set of cartoonish creature pictures that are randomly selected for each user based on their user id.
We used to assign a random picture from the following set via user_id % 15:

Trivia: the first two images were secret ones that only devs can obtain
As you can see, we didn't have a big selection of pictures so with bigger customer organizations,
it could be hard to distinguish users. To solve this, our design team came up with a more personalized
approach to default pictures using people's initials and a random color from our palette. This also
means we would have to render the pictures on the fly using dynamic information about the user.
 a sample of some images from our team
a sample of some images from our team
The business logic in this project is very simple, so we decided on a NodeJS
server using express and image rendering using
node-canvas. The actual rendering code
is less than 50 lines and we had up and running on Heroku within hours.
Trivia: to render Chinese Japanese Korean characters properly, we detect char > '\u2E7F'
and switch to a font that supported CJK characters
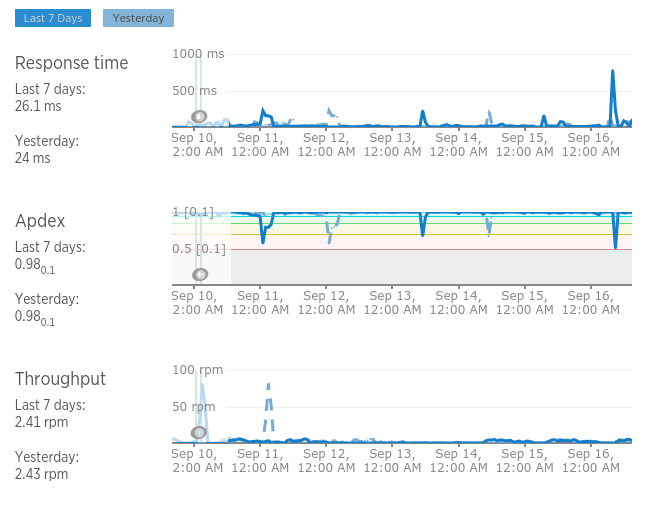
We learned a lot about server side canvas drawing while building this and our production service
has been averaging a blazingly fast 26ms response time.
Check out the open sourced code at
github.com/BetterWorks/defaulter
We even included a convenient Heroku deploy button so that you can get up and running with your own
service in seconds.
04 Sep 2015
·
Clark DuVall
·
This is the story of how we ditched Django REST Framework
Serializers for
serpy and got a performance boost in almost all of our API
endpoints.
Here at BetterWorks, we use a lot of tools to keep tabs on our app and
make sure our API is performing quickly and efficiently. In production, we use New
Relic, and locally we use tools like Django Debug
Toolbar and Python's
profilers. Many times, an endpoint is executing
too many queries, or the queries are inefficient. These problems are usually pretty easy to solve.
Other times, our Python code is the problem.
As I was profiling some of our slower APIs, I went through my checklist:
- Too many SQL queries happening? NOPE
- Slow SQL queries happening? NOPE
- A lot of obvious work being done in Python? NOPE
An example of a typical Django view where I was seeing this pattern looked something like this:
class GoalsView(BaseView):
def get(self, user_id, *args, **kwargs):
goals = Goal.objects.filter(owner_id=user_id)
return Response(GoalSerializer(goals, many=True).data)
Simple right? So I got out one of my favorite tools
RunSnakeRun to visualize the output from
cProfile. It turns out most of the work was being done serializing Django models into the format
needed for the response. We were using Django REST Framework (DRF)
Serializers for this step, and they
were the bottleneck for these APIs.
I took a look into the DRF serializer code, and saw that a lot of work was being done each time the
serializer was used. This was necessary because of the large amount of features the DRF serializers
support, but we didn't use most of these features.
After looking at this, I decided to write my own serialization library that was focused on
simplicity and performance. A couple days later I had the first version of
serpy. One of the key ideas in serpy was pushing as much
work as possible to the serializer's
metaclass. This
means that when actual serialization happens, it is just a simple loop through the fields to be
serialized.
Using serpy, we had a big performance boost in endpoints where the bottleneck was serialization.
This graph shows a simple benchmark between serpy, DRF serializers, and Marshmallow (another popular
serialization framework):
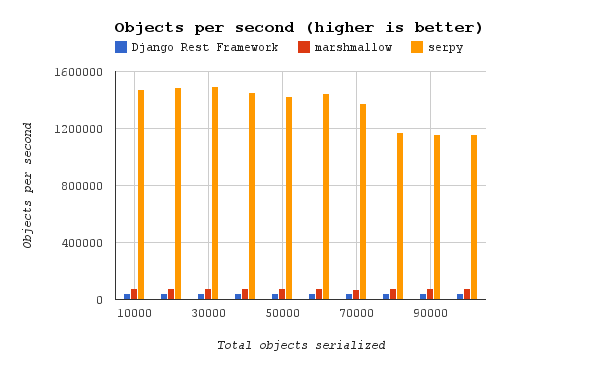
More benchmarks can be found here.
We have been using serpy in production for a few months now, and haven't had any more bottlenecks on
serialization. Django REST Framework is still used for other parts of our app, but serialization
required a more performant library.
03 Sep 2015
·
Rebecca Odim
·
At BetterWorks, we use the Django ORM for data persistence and have found it to be very convenient for modeling and basic querying. It's very easy to use and does a lot of the work for you when it comes to dealing with multiple tables in the database. However, it falls short for some of the more complex queries.
Instead we use SQLAlchemy for these advanced read-only use cases. We use django-sabridge to instantiate SQLAlchemy tables and attach the Bridge() instance to the local thread. One hiccup we've hit while unit testing is that Django models are created and destroyed inside a test transaction, therefore, we had to create a subclass of SQLAlchemy Query to execute queries inside the same database transaction.
Two example use cases of SQLAlchemy in our application are filtering by a function that requires joining a table with itself, and recursive Common Table Expressions (CTE).
Joining Tables
Let's say I have a Goal model that has a progress field and a related parent field also of type Goal,
class Goal(models.Model):
progress = models.IntegerField()
parent = models.ForeignKey('self', related_name='children')
and we want to filter by this formula:
2 * goal.progress <= goal.parent.progress
Filtering by this function is complex in Django ORM because it requires a formula and a join, and aggregates don't handle this easily. It is possible to use queryset.extra() to do this by using a select_related to get the second reference to the goal table. The Django ORM query will automatically join the goal table, named goal, with itself and name the second table T2:
Goal.objects.all()
.select_related('parent')
.extra(select={'compare_progress':
'SELECT * FROM T2 WHERE 2 * goal.progress <= T2.progress'})
This is obviously a huge hack and strongly discouraged. We could do the above query with much more control in raw SQL:
SELECT * FROM goal
JOIN goal AS parents ON goal.parent_id = parents.id
WHERE 2 * goal.progress <= parents.progress
Dealing with raw strings isn't very friendly nor safe, so we rewrite this query using SQLAlchemy.
goal_table = bridge[Goal]
parents_table = aliased(goal_table, name='parents_table')
session.query(goal_table)
.join(parents_table, goal_table.c.parent_id == parents_table.c.id)
.filter(2 * goal_table.c.progress <= parents_table.c.progress)
Recursive CTEs
Another really useful example of the benefits of SQLAlchemy is recursive CTEs. These are impossible with Django ORM and they can improve performance a lot in certain use cases. For example, if we want to get all of a goal's children in one query (including grandchildren, etc.). The SQL would look like this:
WITH recursive children AS (
-- start with the selected goal
SELECT id, name
FROM goal
WHERE id = 1
UNION
-- unioned with children of all the goals in children
SELECT goal.id, goal.name
FROM goal, children
WHERE goal.parent_id = children.id
)
Then we can query into the children table. Unlike in Django ORM, we can duplicate this query in SQLAlchemy and this gives us way more options when writing queries:
goal_table = bridge[Goal]
children = session
.query(goal_table.c.id, goal_table.c.name)
.filter(goal_table.c.id == 1)
.cte(name='children', recursive=True)
children = children.union(
session
.query(goal_table.c.id, goal_table.c.name)
.filter(goal_table.c.parent_id == children.c.id))
These are some cool examples of why SQLAlchemy has been a powerful tool for our application and how it has given us more control over the underlying SQL queries. SQLAlchemy has allowed us to build a complex goal filtering system, which helps our users find the information they need.
26 Aug 2015
·
Di Wu
·
Setting up this blog has been on my to-do list for more than a year. It's long overdue, but I'm extremely excited that we finally have our own engineering blog.
BetterWorks was founded two years ago with big ambitions. I wanted to improve the way companies operate, bring a new level of transparency to our work lives, and most importantly, I wanted to create an environment where our team can learn and thrive. As hackers, we are born to face bigger challenges and build better products.
Over the last two years, we've accumulated various technical and non-technical wisdoms building and operating our enterprise platform. We want to share some of our learnings here with the rest of the community.
Let's all get 1% better every day.